The fastest CSV parser in .NET
Latest update: 2024-01-13, added newcomer Addax.Formats.Tabular, updated several packages, and Sep takes first place with a multithreading support. I moved to .NET 8. I added information about server GC (results have so far just been workstation GC).
Specific purpose tested
My goal was to find the fastest low-level CSV parser. Essentially, all I wanted was a library that gave me a
string[] for each line where each field in the line was an element in the array. This is about as simple as you can
get with a CSV parser. I don’t care about parsing headings or dynamically mapping fields to class properties. I can do
all of that myself faster than reflection with C# Source
Generators, rather trivially.
So if you want a feature-rich library and don’t care as much about 1 millisecond vs 10 milliseconds, read no further and just use CsvHelper. It’s the “winner” from a popularity stand-point and has good developer ergonomics in my experience. Using an established, popular library is probably the best idea since it’s most battle-tested and has the best examples and Q&A online.
Results
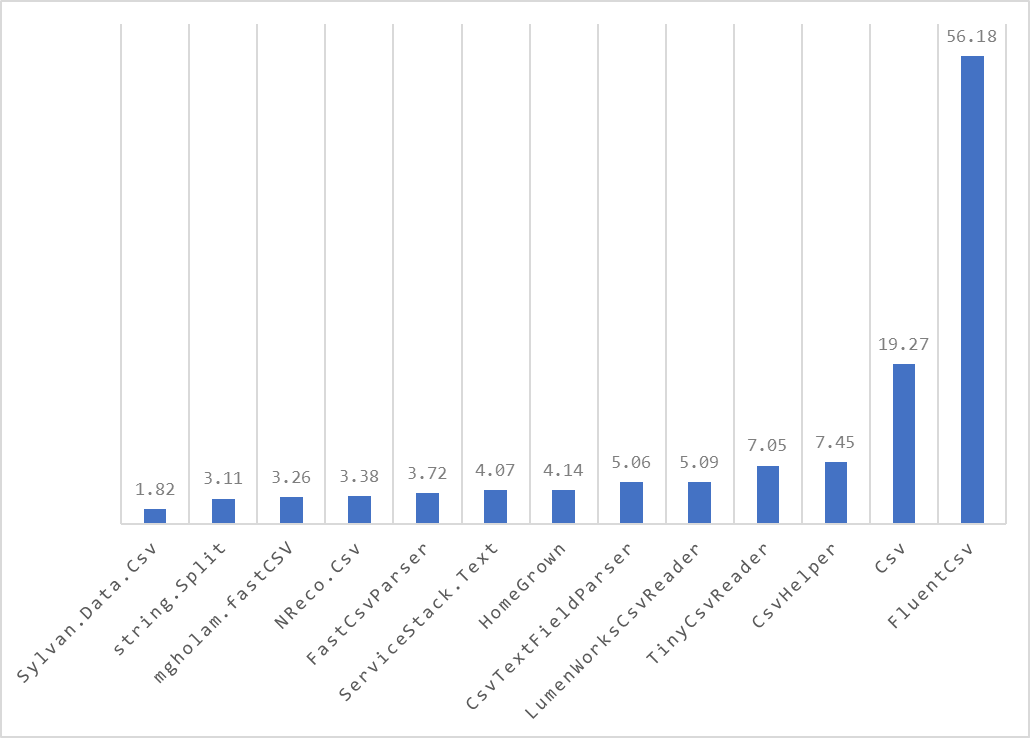
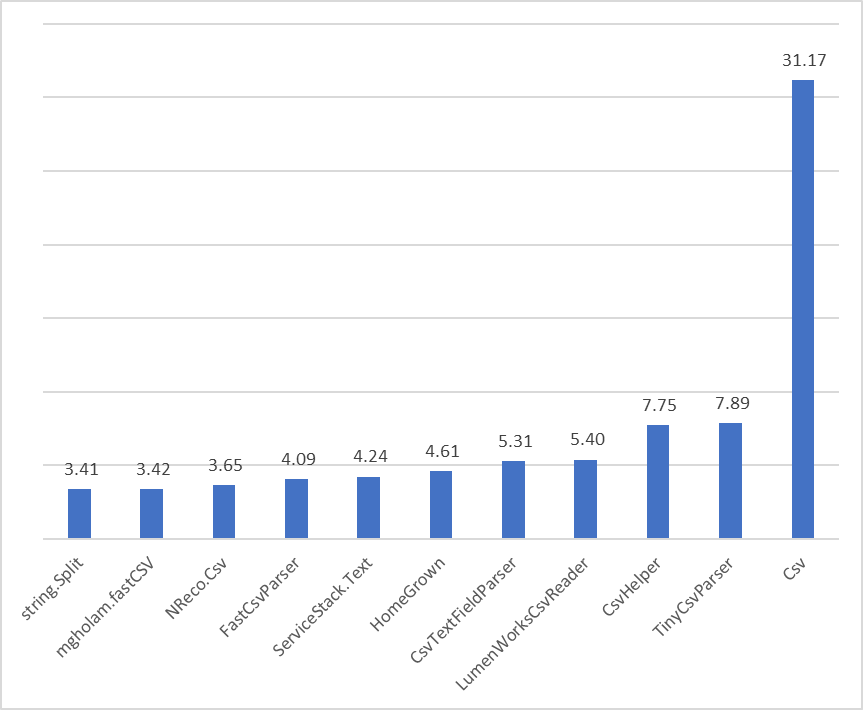
These are the parse times for a CSV file with 1,000,000 lines. The units are in milliseconds. I’ve only shown the top 20 results because the chart was getting hard to read. You can see the other results on 2nd chart below in the update log.
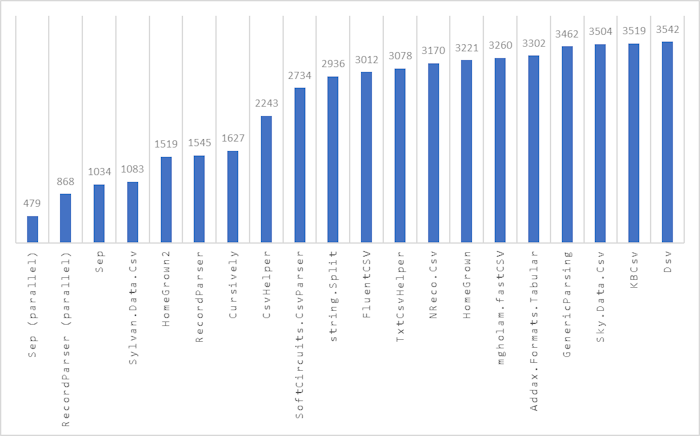
Here are the results for each implementation (see the CSV libraries tested section below for links).
| Rank | Implementation | Workstation GC | Server GC |
|---|---|---|---|
| 1 | Sep (parallel) |
479 ms | 170 ms |
| 2 | RecordParser (parallel) |
868 ms | 387 ms |
| 3 | Sep |
1034 ms | 720 ms |
| 4 | Sylvan.Data.Csv |
1083 ms | 769 ms |
| 5 | HomeGrown2 (HomeGrown with string pooling) |
1519 ms | 1227 ms |
| 6 | RecordParser |
1545 ms | 1171 ms |
| 7 | Cursively |
1627 ms | 1026 ms |
| 8 | CsvHelper |
2243 ms | 1959 ms |
| 9 | SoftCircuits.CsvParser |
2734 ms | 825 ms |
| 10 | string.Split (broken for escaped commas) |
2936 ms | 1042 ms |
| 11 | FluentCSV |
3012 ms | 1143 ms |
| 12 | TxtCsvHelper |
3078 ms | 1108 ms |
| 13 | NReco.Csv |
3170 ms | 1434 ms |
| 14 | HomeGrown (my own implementation) |
3221 ms | 1497 ms |
| 15 | mgholam.fastCSV |
3260 ms | 1553 ms |
| 16 | Addax.Formats.Tabular |
3302 ms | 1413 ms |
| 17 | GenericParsing |
3462 ms | 1653 ms |
| 18 | Sky.Data.Csv |
3504 ms | 1470 ms |
| 19 | KBCsv |
3519 ms | 1753 ms |
| 20 | Dsv |
3542 ms | 1549 ms |
| 21 | ServiceStack.Text |
3624 ms | 1634 ms |
| 22 | CSVFile |
3800 ms | 1819 ms |
| 23 | Microsoft.ML (parallel) |
3885 ms | 823 ms |
| 24 | FileHelpers |
3953 ms | 1855 ms |
| 25 | FastCsvParser |
4152 ms | 1715 ms |
| 26 | CsvTextFieldParser |
4164 ms | 2392 ms |
| 27 | Ctl.Data |
4281 ms | 1452 ms |
| 28 | Open.Text.CSV |
4622 ms | 3697 ms |
| 29 | Cesil |
4623 ms | 3399 ms |
| 30 | LumenWorksCsvReader |
4723 ms | 2879 ms |
| 31 | LinqToCsv |
4983 ms | 3194 ms |
| 32 | TinyCsvReader |
5071 ms | 3186 ms |
| 33 | CsvTools |
5857 ms | 3672 ms |
| 34 | StackOverflowRegex (a StackOverflow implementation) |
6587 ms | 5278 ms |
| 35 | FlatFiles |
6597 ms | 4881 ms |
| 36 | Csv |
7255 ms | 6591 ms |
| 37 | Angara.Table |
7991 ms | 5708 ms |
| 38 | Microsoft.Data.Analysis |
11401 ms | 8835 ms |
| 39 | Microsoft.VisualBasic.FileIO.TextFieldParser (built-in) |
15266 ms | 15693 ms |
| 40 | ChoETL |
18915 ms | 16719 ms |
| 41 | CommonLibrary.NET |
27247 ms | 15460 ms |
🏆 Congratulations Sep! This library has taken the first place by parsing a
1 million line file in 479 milliseconds on workstation GC and a blistering 170
ms on server GC. Do note that this library is only one of the three that is
tested using parallelism in its implementation (RecordParser and
Microsoft.ML being the others). ML.NET has had parallel TextLoader for
some time, although poorly documented, this is on by default in
TextLoader.Options.UseThreads.
If you want to stick to a single threaded parsing library, you can also use
Sep in a single threaded fashion and still get amazing performance.
One thing to consider with Sep (and others) is that escaped fields (double
quotes) will not be unescaped automatically unless you set the Unescape = true
property on the SepReaderOptions. For more information, see Sep’s README on
unescaping. Most other libraries
provide unescaped strings by default, but not all, and some libraries also have
unescaping and/or quotes handling disabled during the above benchmarks like
RecordParser. The impact to performance with automatic unescaping for
Sep is neglible in this benchmark, while RecordParser (parallel) works
best without quote handling/unescaping.
Caveats
Note that this benchmark has several characteristics which may not match your production environment. If you’re concerned about how these results will match up with your own application, I highly recommend running your own performance tests.
The data in this test benchmark has:
- No double quotes in any field value
- No commas in any field value
- No new line characters (
\ra.k.a.CRa.k.a. carriage return or\na.k.a.LFa.k.a. line feed) in any field value - A lot of repeated field values
No double quotes (and no commas and new lines inside such) allows some libraries, like RecordParser (parallel), to skip looking for quotes and only look for commas and new lines. Additionally, it allows skipping keeping track of such quotes and unescaping them, as is default for Sep, which still finds and handles quotes correctly no matter what though. Unlike e.g. RecordParser. For performance of automatic unescaping with Sep see detailed benchmarks in Sep README.
This means that parsers that aren’t particularly fast at handling escaping (e.g. a row like hello,"my good",friend)
might do very well at this benchmark but not perform as well on your data containing a lot of double quotes. For a lot
of repeated values, a parser can implement string pooling (sometimes called “interning”) to reduce allocations. If your
data has few or no repeated values, then a string pool will be unnecessary overhead.
All of the historical results and the current column chart graphics are using workstation GC as opposed to server GC. If you look at the results table above, using server GC can have profound impact on the result and, in this case, changes the results significantly. For example, Microsoft.ML is in the top 5 with server GC but not even in the top 20 with workstation GC.
Finally, Mark Pflug (author of the Sylvan.Data.Csv library) did some great research on new line and quoted field handling in the various CSV parsers. See joelverhagen/NCsvPerf#52 for more information. Perhaps in the future I’ll capture this support in column in the new table above. The point here is that some CSV parsing libraries handle CSV edges better than other libraries.
In general, given the specific characteristics of the data in this benchmark, it is entirely feasible to write a custom fast parallel parser that would beat all of the above since the problem becomes embarrassingly parallel with no quotes. Some libraries are already heavily customized for the data and have custom options that are specific to the benchmark. Please be aware of this and measure on your own data and consult documentation or READMEs for the different libraries.
CSV libraries tested
I tested the following CSV libraries.
- Addax.Formats.Tabular 1.2.0 / Project site / Source code
- Angara.Table 0.3.3 (with 8.0.101
FSharp.Core, 8.0.0System.Collections.Immutable) / Source code - Cesil 0.9.0 / Source code
- ChoETL 1.2.1.64 / Source code
- CommonLibrary.NET ~0.9.8.7 / Source code
- Note: I had to fork this package into Knapcode.CommonLibrary.NET (NuGet.org) for a NuGet.org distribution and for LF handling.
- Csv 2.0.93 / Source code
- CSVFile 3.1.1 / Source code
- CsvHelper 30.0.1 / Project site / Source code
- CsvTextFieldParser 1.2.2 / Source code
- CsvTools 1.0.12 / Source code
- Ctl.Data 2.0.0.2 / Project site / Source code
- Cursively 1.2.0 / Project site / Source code
- Dsv 1.3.1 / Source code
- FastCsvParser 1.1.1 / Source
code
- Note: I had to fork this package into Knapcode.FastCsvParser to avoid a colliding assembly name.
- FileHelpers 3.5.2 / Project site / Source code
- FlatFiles 5.0.4 / Source code
- FluentCSV 3.0.0 / Source code
- GenericParsing 1.5.0 / Source code
- KBCsv 6.0.0 / Source code
- LinqToCsv 1.5.0 / Source code
- LumenWorksCsvReader 4.0.0 / Source code
- mgholam.fastCSV 2.0.9 / Project site / Source code
- Microsoft.Data.Analysis 0.21.0 / Project site / Source code
- Microsoft.ML 3.0.0 / Project site / Source code
- NReco.Csv 1.0.2 / Source code
- Open.Text.CSV 3.4.0 / Source code
- RecordParser 2.3.0 (with 0.1.8
Ben.StringIntern) / Source code - Sep 0.4.0 / Source code
- ServiceStack.Text 8.0.0 / Project site / Source code
- Sky.Data.Csv 2.5.0 / Source code
- SoftCircuits.CsvParser 4.1.0 / Source code
- Sylvan.Data.Csv 1.3.5 (with 0.4.3
Sylvan.Common) / Source code - TinyCsvParser 2.7.0 / Source code
- TxtCsvHelper 1.3.3 / Source code
And… I threw in a few other implementations that don’t come from packages:
- An implementation I called “HomeGrown” which is my first attempt at a CSV parser, without any optimization. 🤞
- “HomeGrown2” which is like “HomeGrown” but has string pooling. Thanks @leandromoh!
- An implementation simply using
string.Split. This is broken for CSV files containing escaped comma characters, but I figured it could be a baseline. - Microsoft.VisualBasic.FileIO.TextFieldParser, which is a built-in CSV parser.
- A regex based CSV-parser from StackOverflow, as suggested by @diogenesdirkx.
I’m talking smack?
Am I defaming your library? Point out what I missed! I make mistakes all the time 😅 and I’m happy to adjust the report if you can point out a legitimate flaw in my test.
I did my best to use the lowest level (and presumably highest performance?) API in each library. If I can adjust my implementations to squeeze out more performance or be more truthful to the intended use of each library API. Let me know or open a PR against my test repository.
Feel free to reach out to me however you can figure out. (can’t make it too easy for the spammers)
My motivation
For my side project NuGet Insights, I was using CSV files as an intermediate data format. Essentially I have an Azure Function writing results to Azure Table Storage and another Function collecting the results into giant CSV files. These CSV files get gobbled up by Azure Data Explorer allowing easy slice and dice with Kusto query language. Kusto is awesome by the way.
To save money on the Azure Function compute time, I wanted to optimize all of the steps I could, including the CSV reading and writing. Therefore, I naturally installed a bunch of CSV parsing libraries and tested their performance 😁.
Methodology
I used BenchmarkDotNet to parse a CSV file I had laying around containing NuGet package asset information generated from NuGet.org. It has a Good Mixture™ of data types, empty fields, and string lengths. I ran several benchmarks for varying file sizes – anywhere from an empty file to one million lines.
I put each library in an implementation of some ICsvReader interface I made up that takes a TextReader and returns a
list of my POCO instances.
I tested execution time, not memory allocation. Maybe I’ll update this post later to talk about memory.
Library-specific adapters
Each library-specific implementation is available on GitHub.
All of the implementations look something like this:
public List<T> GetRecords<T>(MemoryStream stream) where T : ICsvReadable
{
var activate = ActivatorFactory.Create<T>();
var allRecords = new List<T>();
using (var reader = new StreamReader(stream))
{
string line;
while ((line = reader.ReadLine()) != null)
{
var pieces = line.Split(',');
var record = activate();
record.Read(i => pieces[i]);
allRecords.Add(record);
}
}
return allRecords;
}
Code and raw data
The code for this is stored on GitHub: joelverhagen/NCsvPerf
The BenchmarkDotNet and Excel workbook (for the charts and tables above) are here: BenchmarkDotNet.Artifacts-8.0-10.zip
The test was run on my home desktop PC which is Windows 11, .NET 8.0.0, and an AMD Ryzen 9 3950X CPU.
Update log
Update 2024-01-13 (commit 40ae38c)
- Added server GC results
- Switched from IL emit activation to
new T()(thanks Mark for informing me about related perf improvements in .NET!) - Switched from .NET 7 to .NET 8 (8.0.0 runtime, 8.0.100 SDK)
- Added Addax.Formats.Tabular 1.2.0
- Updated BenchmarkDotNet from 0.13.9 to 0.13.12
- Updated FSharp.Core from 7.0.401 to 8.0.101
- Updated GenericParsing from 1.3.0 to 1.5.0
- Updated Microsoft.Data.Analysis from 0.20.1 to 0.21.0
- Updated Microsoft.ML from 2.0.1 to 3.0.0
- Updated RecordParser from 2.1.0 to 2.3.0 (thanks Leandro!)
- Updated Sep 0.2.7 to 0.4.0 and added multithreaded implementation (thanks nietras!)
- Updated ServiceStack.Text from 6.11.0 to 8.0.0
- Updated Sylvan.Common from 0.4.2 to 0.4.3 (thanks Mark!)
- Updated Sylvan.Data.Csv from 1.3.3 to 1.3.5
- Updated System.Collections.Immutable from 7.0.0 to 8.0.0
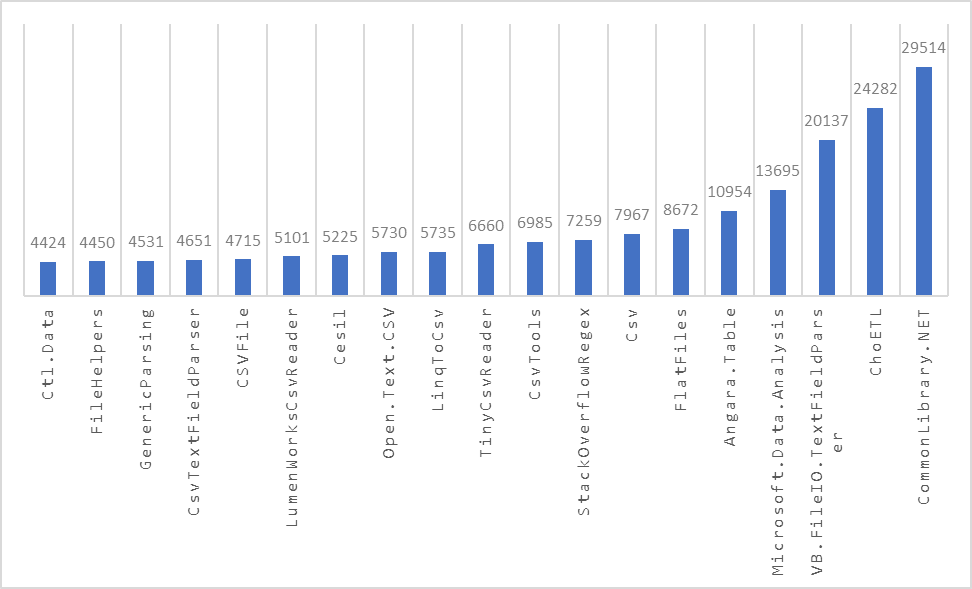
Results - BenchmarkDotNet.Artifacts-8.0-10.zip
Update 2023-10-26 (commit b8b7f1f)
- Updated BenchmarkDotNet from 0.13.5 to 0.13.9
- Updated ChoETL from 1.2.1.50 to 1.2.1.64
- Updated CSVFile from 3.1.0 to 3.1.1
- Updated FSharp.Core from 7.0.200 to 7.0.401
- Added GenericParsing 1.3.0
- Added HomeGrown2
- Updated NReco.Csv from 1.0.1 to 1.0.2
- Updated Open.Text.CSV from 3.3.3 to 3.4.0
- Updated RecordParser from 1.3.0 to 2.1.0 and added a separate “parallel” benchmark
- Added Sep 0.2.7
- Updated ServiceStack.Text from 6.7.0 to 6.11.0
- Updated SoftCircuits.CsvParser from 4.0.0 to 4.1.0 and switched to recommended API
- Updated Sylvan.Common from 0.4.1 to 0.4.2
- Updated Sylvan.Data.Csv from 1.2.7 to 1.3.3
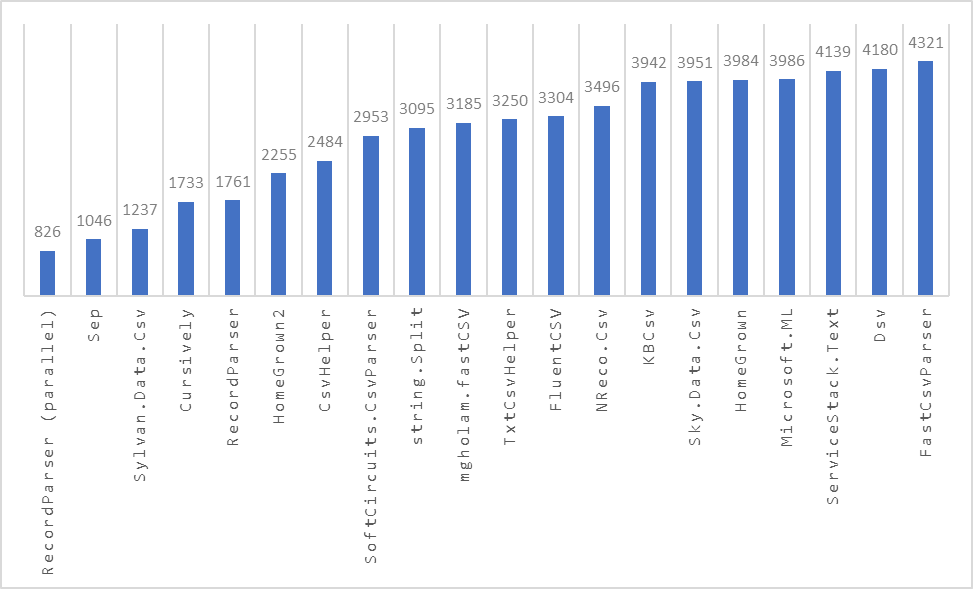
Results - BenchmarkDotNet.Artifacts-7.0-9.zip
Update 2023-03-17 (commit d201f24)
- Switched from .NET 6 to .NET 7 (7.0.4 runtime, 7.0.202 SDK)
- Updated BenchmarkDotNet from 0.13.1 to 0.13.5
- Updated ChoETL from 1.2.1.22 to 1.2.1.50
- Updated Csv from 2.0.62 to 2.0.93
- Updated CSVFile from 3.0.2 to 3.1.0
- Updated CsvHelper from 27.1.1 to 30.0.1
- Updated CsvTextFieldParser from 1.2.1 to 1.2.2
- Updated FileHelpers from 3.5.0 to 3.5.2
- Updated FlatFiles from 4.16.0 to 5.0.4
- Updated Microsoft.Data.Analysis from 0.18.0 to 0.20.1
- Updated Microsoft.ML from 1.6.0 to 2.0.1
- Updated NReco.Csv from 1.0.0 to 1.0.1
- Updated Open.Text.CSV from 2.4.0 to 3.3.0
- Updated RecordParser from 1.2.0 to 1.3.0
- Updated ServiceStack.Text from 5.11.0 to 6.7.0
- Updated SoftCircuits.CsvParser from 3.0.0 to 4.0.0
- Updated Sylvan.Common from 0.2.1 to 0.4.1
- Updated Sylvan.Data.Csv from 1.1.6 to 1.2.7
- Updated System.Collections.Immutable from 5.0.0 to 7.0.0
- Updated TinyCsvParser from 2.6.1 to 2.7.0
- Updated TxtCsvHelper from 1.3.1 to 1.3.3
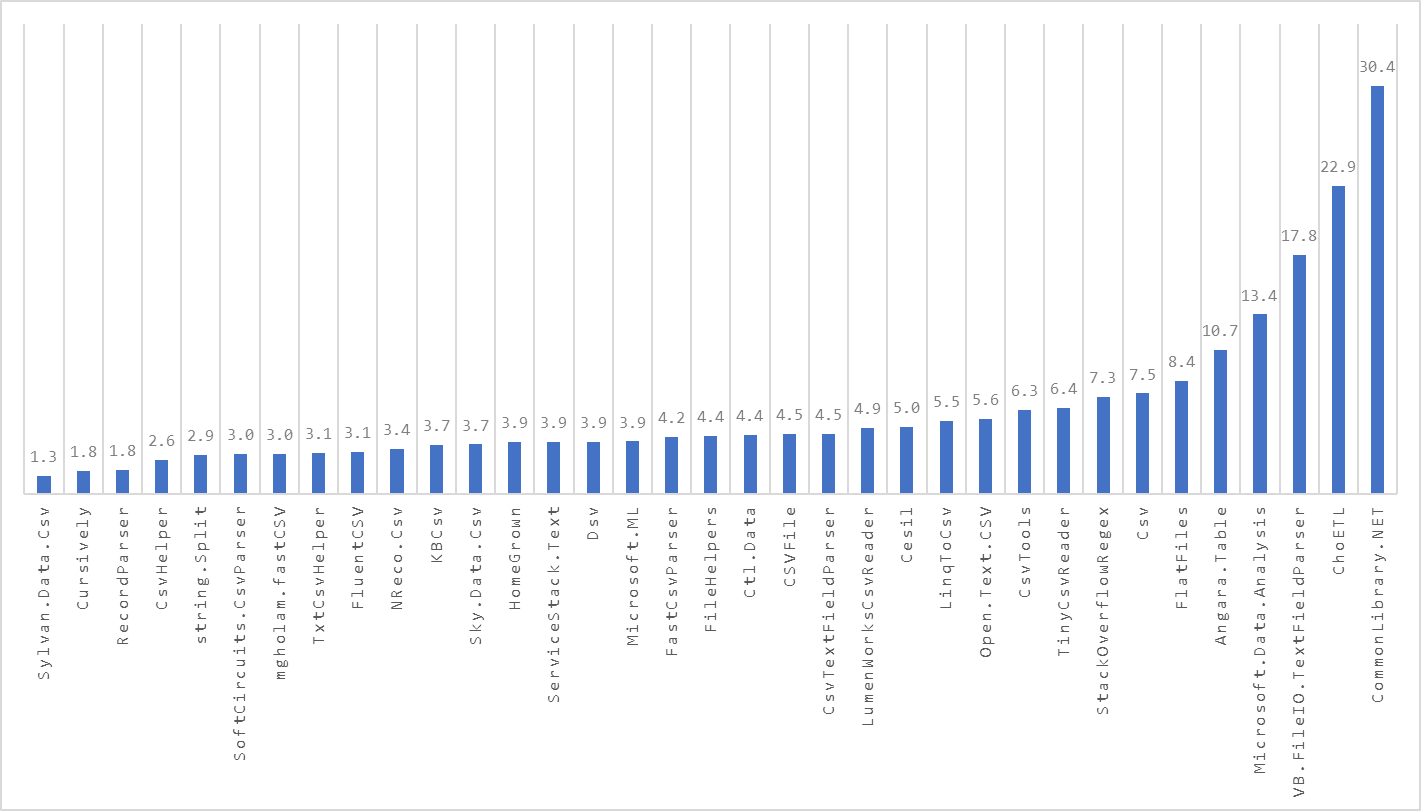
Results - BenchmarkDotNet.Artifacts-7.0-8.zip
Update 2021-08-13 (commit 39dd976)
- Switched from .NET 5 to .NET 6 (6.0.100-preview.7.21379.14)
- Updated Angara.Statistics from 0.1.0 to 0.1.4
- Updated BenchmarkDotNet from 0.13.0 to 0.13.1
- Updated Open.Text.CSV from 2.3.3 to 2.4.0
- Updated Sylvan.Data.Csv from 1.1.5 to 1.1.6
This entire update was done by Mark via a PR. Thanks!
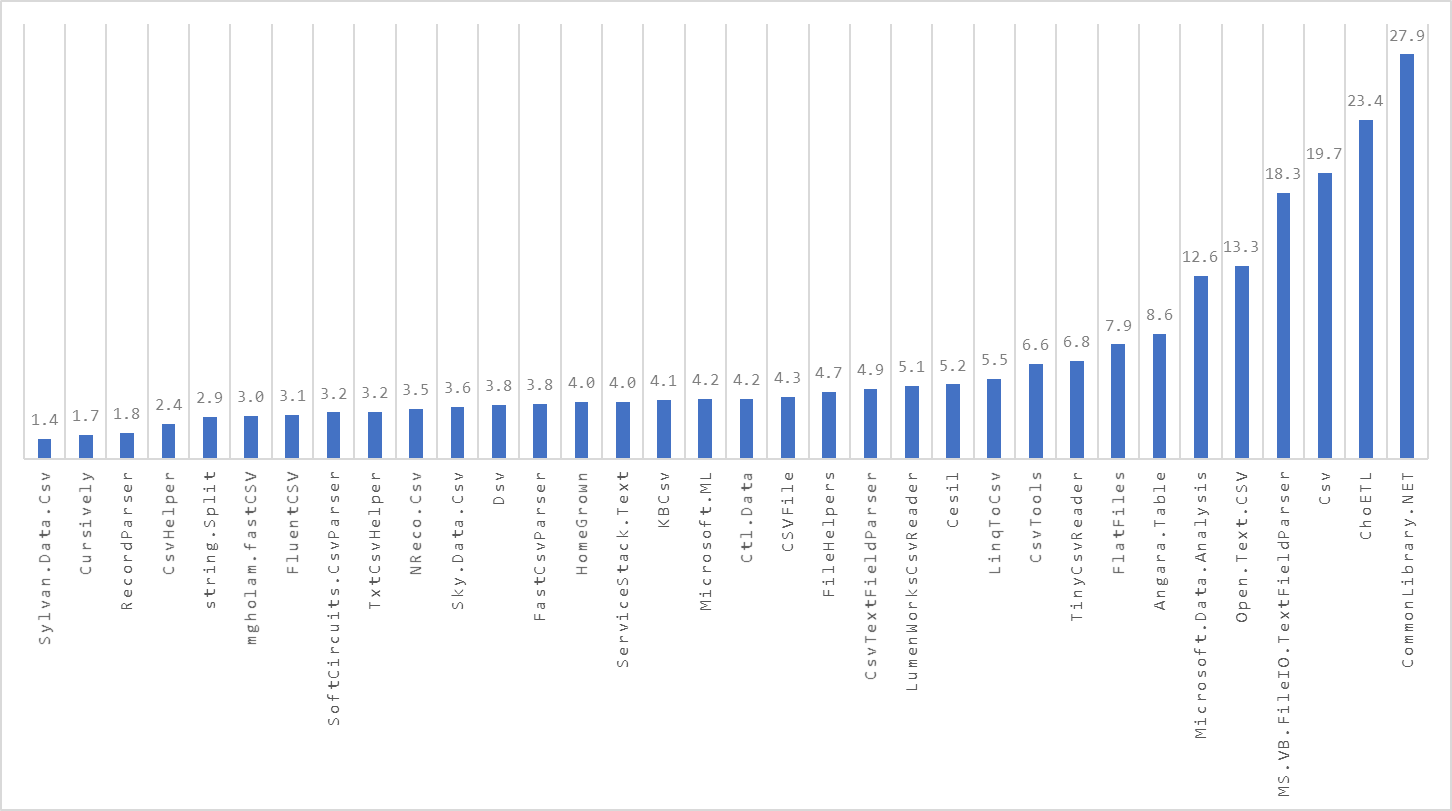
Results - BenchmarkDotNet.Artifacts-6.0-7.zip
Update 2021-08-09 (commit 8fa7626)
- Added Angara.Table via a PR.
- Updated ChoETL from 1.2.1.18 to 1.2.1.22 and enhanced the adapter for 3x perf wins via a PR.
- Added Cesil via a PR.
- Added Dsv via a PR.
- Added KBCsv via a PR.
- Added Microsoft.Data.Analysis via a PR.
- Added Microsoft.ML via a PR.
- Added Open.Text.CSV via a PR.
- Updated Sylvan.Data.Csv from 1.0.3 to 1.1.5 via a PR.
- Updated TxtCsvHelper from 1.2.9 to 1.3.1 via a PR.
This entire update was done by Mark. Thanks so much ❤️!
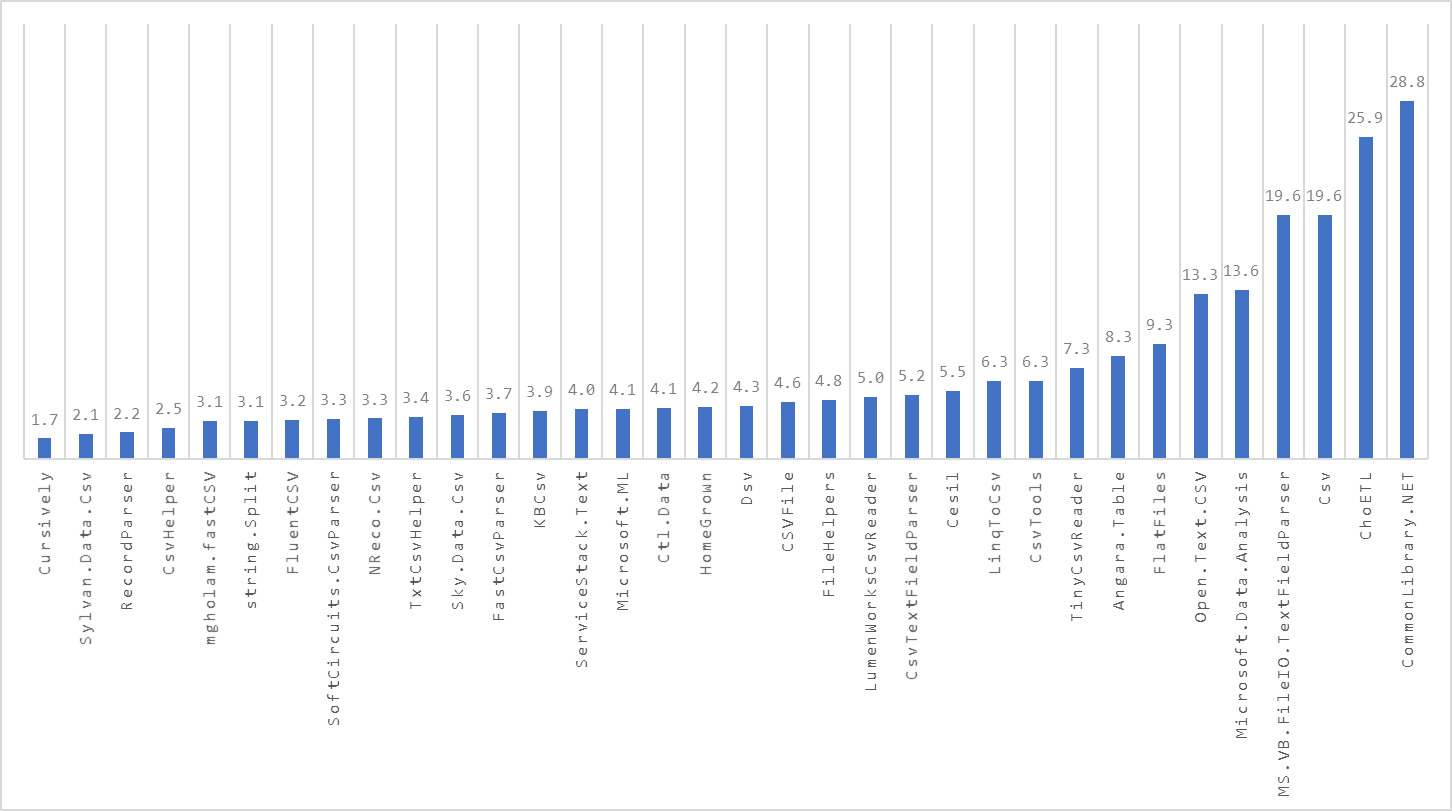
Results - BenchmarkDotNet.Artifacts-5.0-6.zip
Update 2021-08-05 (commit a26df9c)
- Updated CsvHelper from 27.1.0 to 27.1.1.
- Updated FlatFiles from 4.15.0 to 4.16.0.
- Added RecordParser via a PR. Thanks Leandro!
- Updated TinyCsvParser from 2.6.0 to 2.6.1.
- Added TxtCsvHelper via a PR. Thanks Cameron!
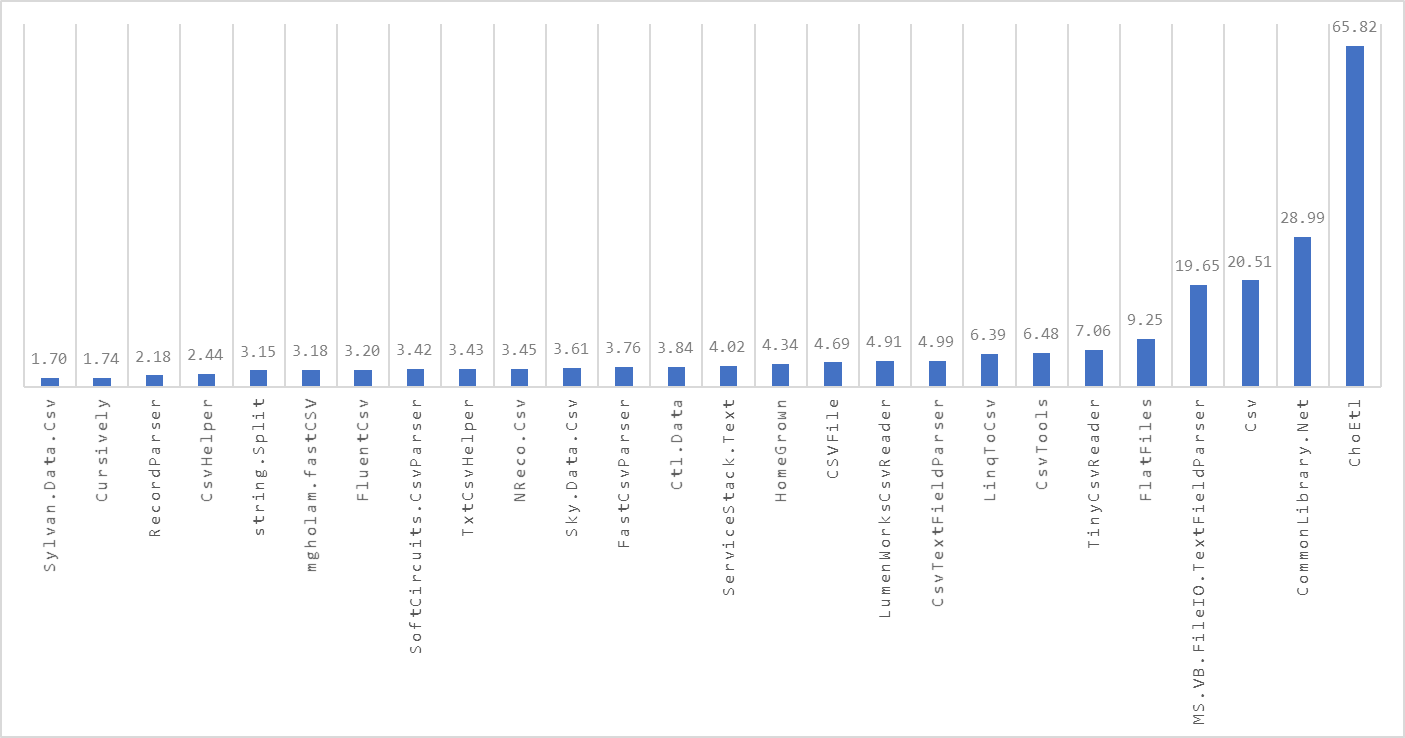
Results - BenchmarkDotNet.Artifacts-5.0-5.zip
Update 2021-06-16 (commit 514a037)
- Added ChoETL via a PR. Thanks, Josh!
- Added CommonLibrary.NET via a PR. Thanks, Josh!
- Added CSVFile via a PR. Thanks, Josh!
- Updated CsvHelper from 20.0.0 to 27.1.0.
- Added CsvTools via a PR. Thanks, Josh!
- Added FlatFiles via a PR. Thanks, Josh!
- Updated FluentCSV from 2.0.0 to 3.0.0 via a PR. Thanks Aurélien!
- Added LinqToCsv via a PR. Thanks, Josh!
- Updated ServiceStack.Text from 5.10.4 to 5.11.0.
- Updated SoftCircuits.CsvParser from 2.4.3 to 3.0.0.
- Added Sky.Data.Csv via a PR. Thanks, Josh!
- Updated Sylvan.Data.Csv from 0.9.0 to 1.0.3 via a PR and a subsequent change by me. Thanks, Mark!
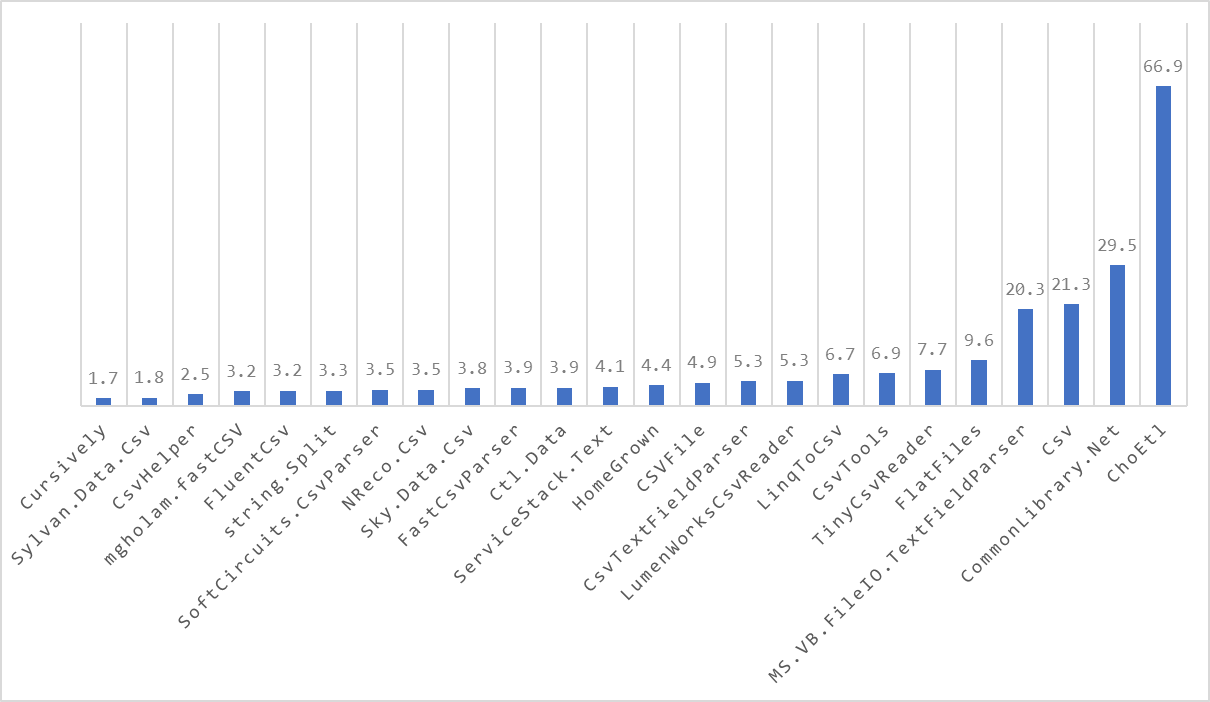
Results - BenchmarkDotNet.Artifacts-5.0-3.zip
Update 2021-01-18 (commit 8005d5)
- Added Ctl.Data by request.
- Added Cursively via a PR from @airbreather. Thanks, Joe!
- Added Microsoft.VisualBasic.FileIO.TextFieldParser by request.
- Added SoftCircuits.CsvParser by request.
- Updated CsvHelper from 19.0.0 to 20.0.0 via a PR from @JoshClose. Thanks, Josh!
- Updated ServiceStack.Text from 5.10.2 to 5.10.4.
- Updated Sylvan.Data.Csv from 0.8.2 to 0.9.0.
- Switched to a fork of FastCsvParser to avoid duplicate DLL name.
Results - BenchmarkDotNet.Artifacts-5.0-2.zip
Update 2021-01-06 (commit 586f602)
- Moved to .NET 5.0.1
- Added FluentCSV by request.
- Added Sylvan.Data.Csv via a PR from @MarkPflug. Thanks, Mark!
- Updated Csv from 1.0.58 to 2.0.62.
- Updated CsvHelper from 18.0.0 to 19.0.0.
- Updated mgholam.fastCSV from 2.0.8 to 2.0.9.
Results - BenchmarkDotNet.Artifacts-5.0.zip
Initial release 2020-12-08 (commit 57c31a)
Results - BenchmarkDotNet.Artifacts.zip