How to run a distributed scan of Azure Table Storage
Series
This post is part of my Advanced Azure Functions series (thanks for the idea, Loïc!)
- How to run a distributed scan of Azure Table Storage - this post
- Disk write performance on Azure Functions - use the Azure File Share efficiently
- Run Azure Functions on Virtual Machine Scale Sets - save $$$ on Functions
Introduction
Suppose you have a massive table in Azure Table Storage and you need to perform some task on every single row. In my case, I am using Azure Table Storage to record the latest NuGet V3 catalog leaf for each package ID and version. After this table is created, I want to enqueue an Azure Queue Storage message for each package ID and version (each row in the table). In other words, I’m using Azure Table Storage to deduplicate work items via row-level concurrency controls (etags) before enqueueing the work item for each row. In my case, the NuGet V3 catalog often has multiple catalog leaves for package ID and version, and I only want to process the latest leaf.
Getting every single row in an Azure Table can be done in many ways. The simplest approach would be to use the segmented query API and pagination to get blocks of 1000 entities at a time, in a serial fashion, and perform whatever action you need on those segments. The C# code could look something like this:
The “serial” approach
This sequentially fetches all records in a single Azure Table.
CloudTable table = GetTable("mystoragetable");
var tableQuery = new TableQuery { TakeCount = 1000 };
TableContinuationToken continuationToken = null;
do
{
// Get the next segment
TableQuerySegment segment = await table.ExecuteQuerySegmentedAsync(
tableQuery,
continuationToken);
// Process the segment however you want
// Continue to the next segment
continuationToken = segment.ContinuationToken;
}
while (continuationToken != null);
Problem
This serial probably works in many scenarios but it starts to fall over if the table is really big. Suppose you have a table with many millions of rows and many hundreds of thousands of partition keys. Depending on your execution environment, you may not be able to perform that sequential pagination of the entire table within some time limit. For example, Azure Function’s consumption plan has a maximum execution duration of 10 minutes.
From some of my testing, I found that it takes about 8 minutes to serially page through 3.5 million records in Azure when the storage account is in the same region (I tested West US 2). If my data grows much more, I won’t be able to fetch all of the data within a single Azure Function execution. And this duration doesn’t account for any logic on each row. If I do a somewhat costly operation on each entity, then there’s no way I can finish the work before the timeout.
So what are the options? Well, I could improve the serial approach and record the continuation token after
each segment. This way, upon timeout, I could resume at the latest continuation token point (i.e. that is
x-ms-continuation-NextPartitionKey and x-ms-continuation-NextRowKey values).
Also, I could enqueue a message (e.g. Storage Queue, Service Bus, etc) for each segment or entity so that the “paging” code is doing as little work as possible and some other code running in parallel is processing the entities. This is a producer-consumer approach.
Another option would be to only query for a single segment at a time. After a segment is fetched, I could enqueue a follow-up message containing the next continuation token. This would make break the paging operation up into a lot of little Azure Function executions, thus avoiding the maximum execution time.
But these are still single-threaded, serial approaches. The duration of the paging operation is linearly related to the number of rows in the table.
How could we parallelize this scan of the Azure Table? Ideally, we can throw a bunch of Azure Function nodes at the work: both querying for rows and processing said rows. At face value, the Azure Table Storage APIs only allow the discovery and enumeration of partition keys and row keys using this serial API. But we can be clever!
Idea: recursively discover partition key prefixes
One capability that the Azure Table Storage has is that you can query for partition keys greater than X. With carefully crafted parameters, this can be leveraged to enumerate the prefixes of all partition keys. This logic can be executed recursively to discover all partition keys in the table after the first “layer” of prefixes is discovered. Finally, this “recursion” work can be distributed across many nodes without any fear of two workers querying for the same record. In other words, each query will be discovered only once
Let me explain. Suppose you have a small table like this, where the partition key is a fake person’s last name and the row key is the first name:
| PartitionKey | RowKey |
|---|---|
| Dashner | Cleopatra |
| Davis | Gemma |
| Davis | Loralee |
| Dodge | Lowell |
| Hartlage | Marketta |
| Nuckles | Timmy |
| Rundle | Coleen |
| Splawn | Lise |
| Wedell | Annabelle |
| Wongus | Rosenda |
The maximum take count (segment size) in Azure Table Storage is 1000, but let’s use a smaller number of 2 to demonstrate the concepts.
We can discover the prefixes D (from Dashner), H (from Hardlage), N, R, S, and W without querying for
every single row. Visually, the query execution would something like this:

The blue nodes are prefix queries. The beige nodes are partition key queries. The green nodes are result sets. PK is
short for PartitionKey and RK is short for RowKey.
We’ve essentially constructed a trie from an unknown data set, right?
In English, consider the following flow of logic:
- Query for a segment with no filter:
- Query:
fetch 2 entities, no filter - Result: two rows returned:
Dashner, CleopatraandDavis, Gemmawith a continuation token - What we learned:
Dis the 1st prefix.
- Query:
- Query for a segment, skipping
D.- Query:
fetch 2 entities, where PK > 'D\uffff'(\uffffis the largest character, an invalid code point) - Result: two rows returned:
Hartlage, MarkettaandNuckles, Timmywith a continuation token - What we learned:
His the 2nd prefix,Nis the 3rd prefix
- Query:
- Query for a segment, skipping
N.- Query:
fetch 2 entities, where PK > 'N\uffff' - Result: two rows returned:
Rundle, ColeenandSplawn, Lisewith a continuation token - What we learned:
Ris the 4th prefix,Sis the 5th prefix
- Query:
- Query for a segment, skipping
S.- Query:
fetch 2 entities, where PK > 'S\uffff' - Result: two rows returned:
Wedell, AnnabelleandWongus, Rosendawithout a continuation token - What we learned:
Wis the 5th prefix and last prefix (since no continuation token was returned)
- Query:
With 4 queries returning a total of 8 rows, we found the prefixes for all entities in the table. We also fetched 8 entities that can be processed immediately.
In addition to the prefixes, we also found 3 segments that have more undiscovered data as indicated by a returned continuation token.
We can continue the process by executing the same logic as above recursively but using the prefixes already discovered.
- From step #1 above, we are not sure whether there are more
Davisrecords.- Query:
fetch all entities with PK = 'Davis' and RowKey > 'Gemma' - Result:
Davis, Loralee - What we learned: we now know all of the
Davisrecords
- Query:
- From step #1 above, we are not sure whether there are more
D*records.- Query:
fetch 2 entities, where PK > 'Davis' and PK < 'D\uffff'without a continuation token - Result:
Dodge, Lowell - What we learned: we know all of the
D*records now
- Query:
Similar logic could be applied to N* and S*. We don’t need to expand W* because no continuation token was returned
for step #4 above.
Applying the idea
So how is this better than just paging through the entities? Well, if your data is bigger than the example above. You can discover every single character prefix of your partition keys in N queries, where N is the number of prefixes.
Think of these prefixes like bookmarks in a dictionary. You have a bookmark at the beginning, for words starting with ‘A’ then another one for ‘B’, etc – 26 in all. After that single actor discovers the initial “layer” of bookmarks, he can hand each section off to another actor who can process that isolated section. One actor gets all of the A’s, another gets all of the B’s, etc. These prefixed sections can be operated on in parallel. Each section can be further broken up into smaller sections. Like the ‘A’ section can be broken up with ‘AA’, ‘AB’, etc.
Imagine this can be done in a distributed manner across dozens of Azure Function nodes. For each prefix of length 1 discovered in the initial phase, enqueue a message. Any partition key queries can be evaluated immediately or deferred in a queue message. Any records found can be processed immediately or deferred with a queue message.
As the Azure Functions orchestrator sees the number of queue messages grow, it will allocate more and more nodes. This way you can throw a bunch of hardware at a big table.
In short, this approach enables truly parallelized processing of partition keys after some relatively cheap discovery stage.
Implementation
Naturally, I have already implemented this idea and tested its performance against a big Azure Table. In my case, the partition key is a NuGet package ID and the row key is a package version. Here’s what the data looks like in Azure Storage Explorer.
I wrote a class called TablePrefixScanner which implements the logic above. It’s available in my GitHub project ExplorePackages:
Implementation: TablePrefixScanner.cs
It has some supporting classes but the core of the logic is here.
To demonstrate the recursion simply, I have implemented a ListAsync method that yields entities in the natural
order of the table (ordered first by PartitionKey then by RowKey). It uses a stack data structure and is therefore
a depth-first search.
Simple usage: ListAsync
This is no better than the serial approach first mentioned above, but it’s useful for showing how to deal with the various “steps” of the algorithm as well as comparing the results to the baseline approach for verifying correctness.
To test the distributed, parallelized usage of this class, I wrote an Azure Queue Storage function that uses the
TablePrefixScanner class to distribute the copying of the entire table to another table. This operation is very
easily distributed (each row can be copied without affected other rows). It uses Azure Queue Storage so it is
a breadth-first search (roughly… since ordering is not guaranteed in Azure Queue Storage).
Distributed usage:
- Queue message handler:
TableCopyMessageProcessor.cs - Enqueueing logic:
EnqueuePrefixScanStepsAsync - The work done, per partition key group:
TableRowCopyMessageProcessor.cs
Performance
I tested the performance of the baseline serial approach and the parallelize approach using my prefix scanner. So that the comparison was as fair as possible, I tried to make the two variants as similar as possible.
Parameters
For a test, I ran a “table copy” routine. Each table row is copied from a source table to a destination table. Rows found by the paging routing are grouped by partition key and enqueued. These partition key batches are processed in a separate Function execution, i.e. not the same Function execution as the code that’s enumerating the rows.
Here are some other common settings between the serial approach and the prefix scan approach:
- Used Azure Functions Consumption plan
- Executed in West US 2
- The Consumption plan and Storage account were doing nothing else during the test
- The same source table was used
- The destination table is empty
The core of the baseline, serial implementation is here: ProcessSerialAsync.cs
Results - 3.5 million records
In this test, 3,558,594 rows were copied from a source table to a destination table.
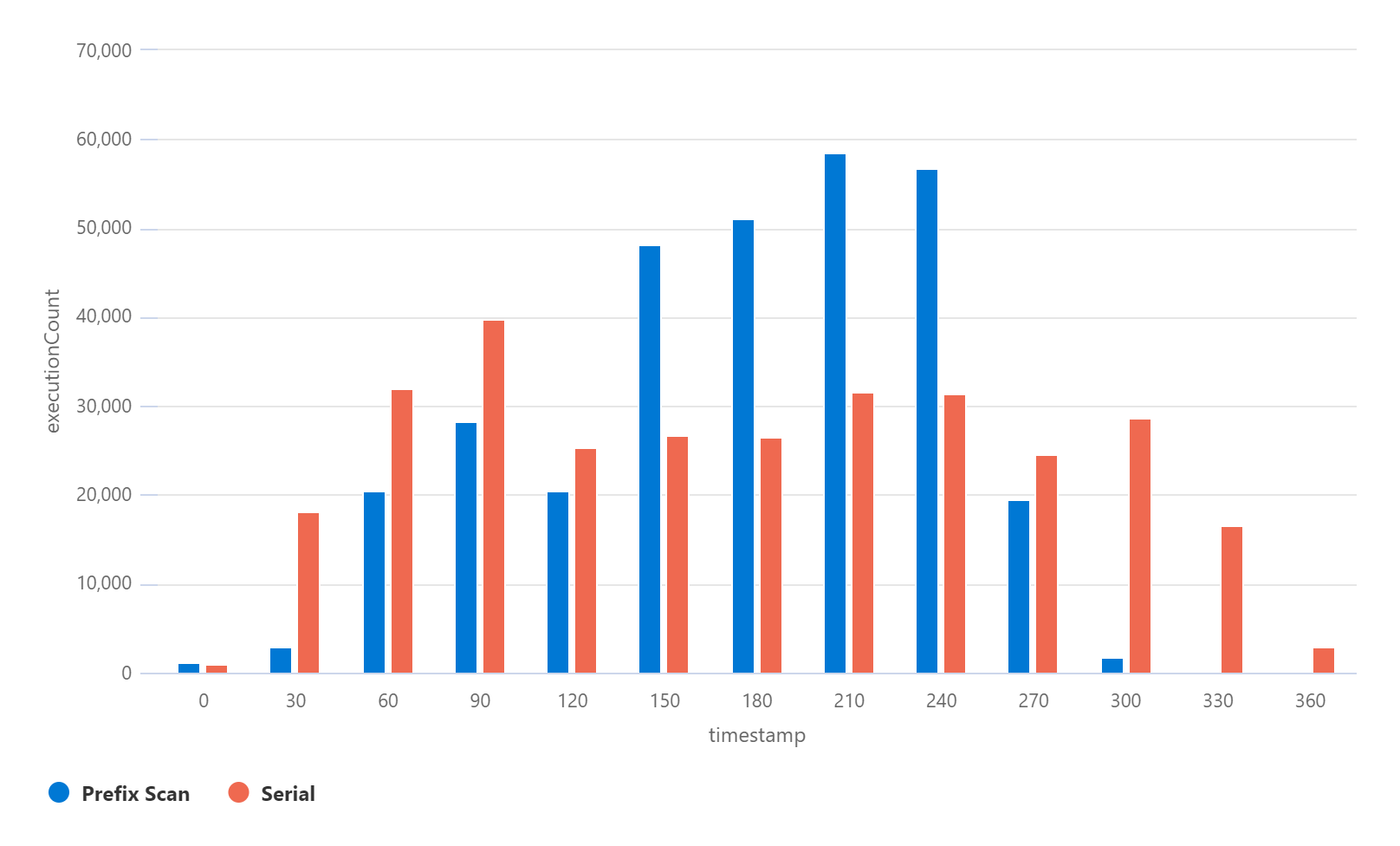
The Y-axis is the number of function executions and the X access is the number of seconds since the process started.
| Variant | Duration | Max executions / 30 seconds | Max execution duration |
|---|---|---|---|
| Serial | 6 minutes | 39,816 | 5 minutes, 21 seconds |
| Prefix Scan | 5 minutes | 58,471 | 7.8 seconds |
As you can see, the serial approach is a bit slower at this table size. The real kicker is the 5 minute, 21 second execution time for the serial approach. This is the single “paging” Azure Function that enqueued the rest of the work.
The serial implementation comfortably finishes within the 10-minute limit. But what if the data doubles?
Results - 7 million records
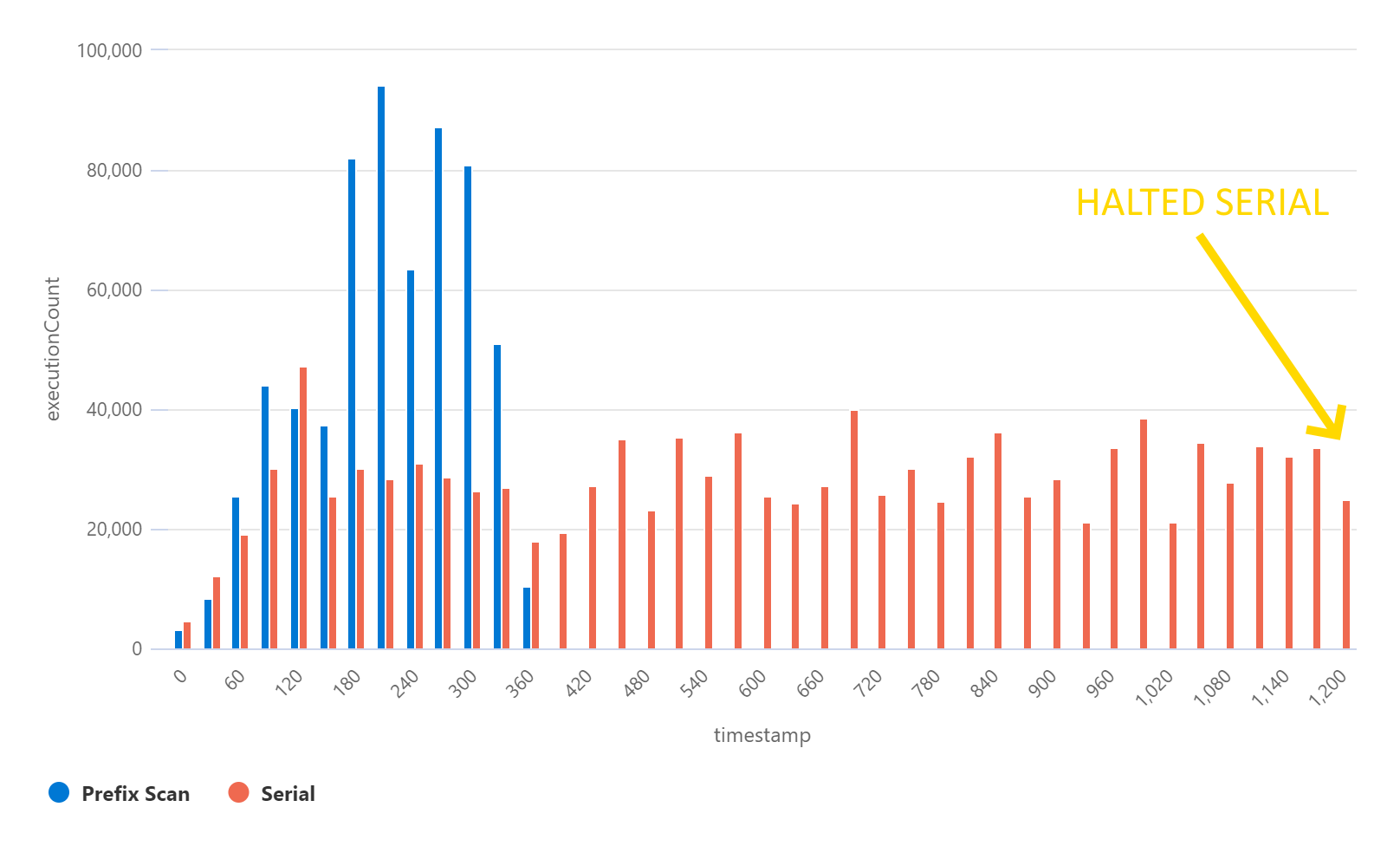
| Variant | Duration | Max executions / 30 seconds | Max execution duration |
|---|---|---|---|
| Serial | forever! | 47,374 | >10 minutes (timeout) |
| Prefix Scan | 6 minutes | 94,134 🔥 | 11.5 seconds |
In this test, the serial approach never completed. After 20 minutes, I halted the process since I could see several Azure Function timeout exceptions. I could also see that the “paging” Function execution had started over from the beginning.
I could add some “checkpoint” code which saves the continuation token in the serial approach allowing it to complete, but as you can see the throughput of this approach hits some maximum, likely based on the network speed between Azure Functions and Azure Table Storage or the latency of the Azure Table Storage REST APIs.
Results - 35 million records
For fun, I wanted to see how hot this prefix scan approach could get.
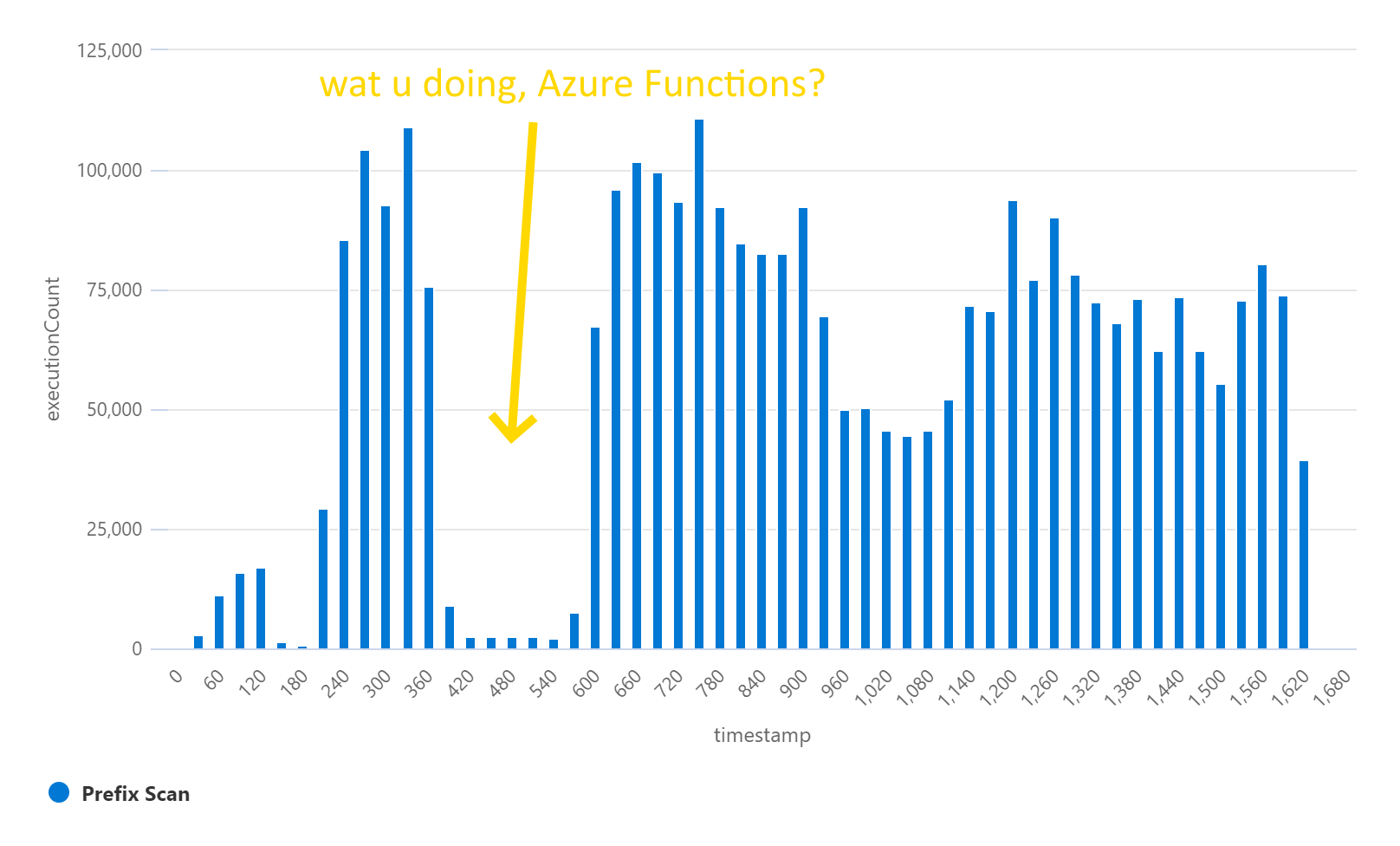
| Variant | Duration | Max executions / 30 seconds | Max execution duration |
|---|---|---|---|
| Prefix Scan | 28 minutes | 110,857 | 2 minutes, 57 seconds |
It seems there is another bottleneck I am running into. I’m not sure what. I noticed the queue size was quite large for most of the test duration, which suggests more hardware could help the problem. Maybe Azure Functions said “no more nodes!”. Not sure.
Other ideas
The way I have the code written right now is that it enumerates all partition keys and row keys. Perhaps you only care about individual partition keys? Well, the code could be modified easily to skip the specific “partition key” query and only do prefix queries. This would improve the performance but delegate and row-level discovery downstream.
Also, this general approach can work anywhere an API allows fast “greater than” query capabilities on a string ID field.
Although Azure Blob Storage doesn’t provide a “greater than” operator, I think it may be possible to utilize the prefix
and arbitrary delimiter parameters
for a similar effect.
Finally, this is probably an overly complex solution for some scenarios. Since Azure Table Storage doesn’t support indexes and only a very limited number of query patterns are supported, it’s often best to duplicate data. So if you want to scan the entire table, it could be easier to just store a list of all partition keys separately from the data itself, akin to Stack Overflow question “Is there a way to get distinct PartionKeys from a Table”.
Conclusion
I can confidently say the prefix scan approach is over 2 times faster than the serial approach with a decent chance for even better performance if dedicated compute (non-Consumption plan) is used.
Feel free to use copy to code out for your own projects! It’s under the MIT license.
Code: src/ExplorePackages.Logic/Storage/TablePrefix
Tests: TablePrefixScannerTest.cs
If there’s some interest, I can package it up in a NuGet package for easier consumption. Right now, I’m feeling that this topic is a bit esoteric 😅.